前言
在不同的系统或者同一个系统的不同实例间共享某个临界资源,为防止互相影响往往需要通过加锁的方式来将二者互斥开来。分布式锁就是在分布式系统中将多个同时对临界资源进行的操作互斥开的一种方式。
当我们遇到并发的对某个资源进行操作的场景时经常第一时间想到的是利用Redis、ZK等中间件加分布式锁来保证数据的准确性和一致性,但是在一些场景下并不一定需要显式的加锁来解决这个问题。
背景
这天亚瑟和胖虎遇到如下的一个业务场景:
假设一条记录中包含两个字段:A和B,同时存在两个业务逻辑:
A逻辑:更新A字段值为1,同时判断B字段值是否为1,如果是则通知下游删除数据
B逻辑:更新B字段值为1,同时判断A字段值是否为1,如果是则同步数据给下游时携带删除标记
思考一分钟,一般会怎么做呢?
几种解决办法
Option 1
不假思索的亚瑟先提出了一个大胆的想法:执行逻辑前先查一下数据,在执行逻辑时判断对方的字段是否有更新,操作流程如下:
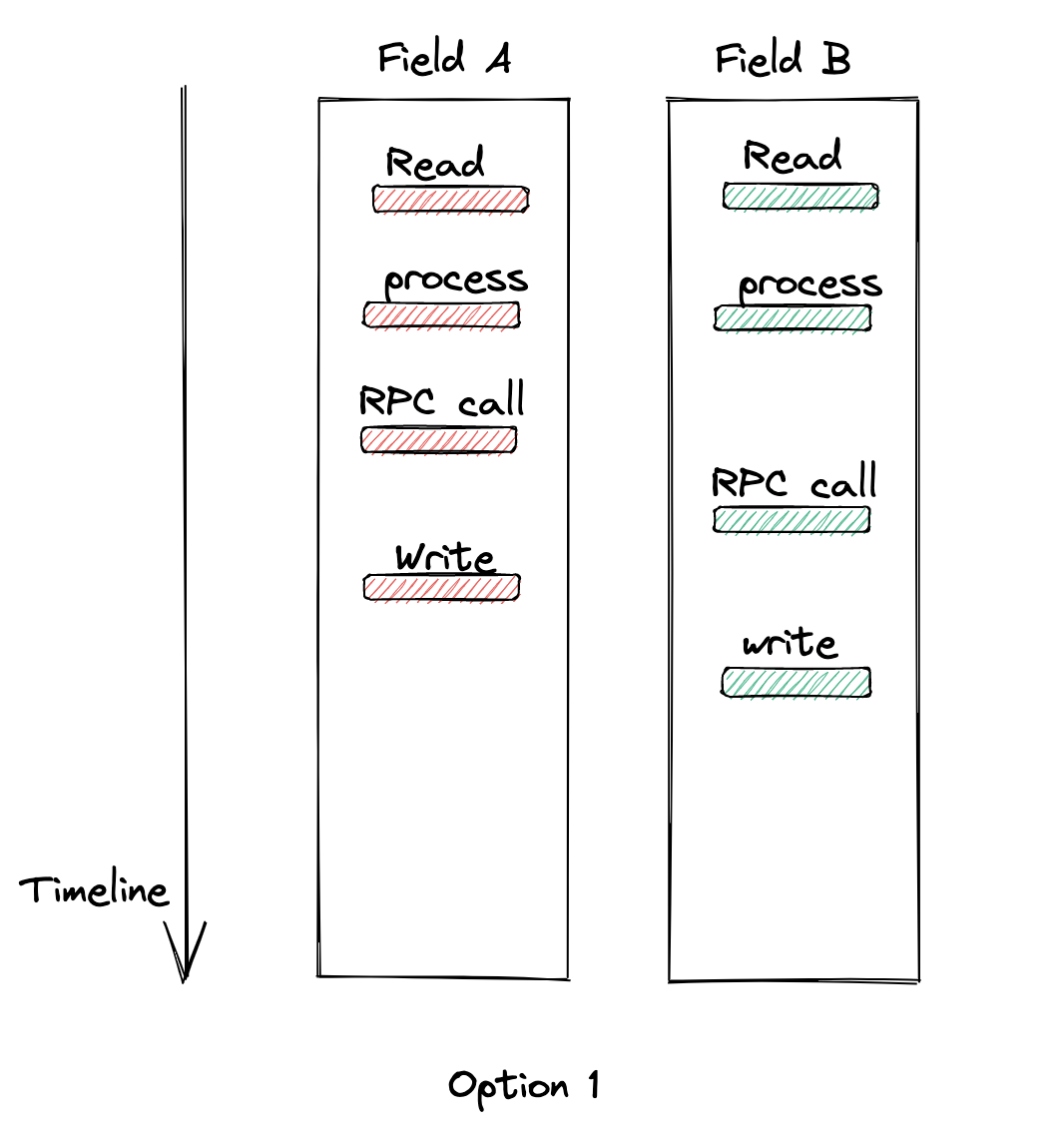
但是当两个操作并发执行的时候A、B的两次读取都恰好读到对方字段没有发生变更,最终下游没有接到任何的删除通知,导致逻辑出错。
Option 2
为了补救上一种解法存在的问题,亚瑟提出一个更大胆的想法:在处理完自身逻辑通知下游前再查一次数据,这样如果是在处理逻辑时刚好对方字段有更新那就可以查到最新的数据,然后根据最新的数据判断是否要通知下游进行删除。
可真是个小机灵,问题解决,代码关闭,王者荣耀启动,让我康康今天谁还能阻止亚瑟成为峡谷中的王者!
但仔细一想虽然在通知下游前查询了一次最新数据,但依然没有解决问题,有可能会出现通知下游前的那次查询查到的还是旧数据,具体流程如下:
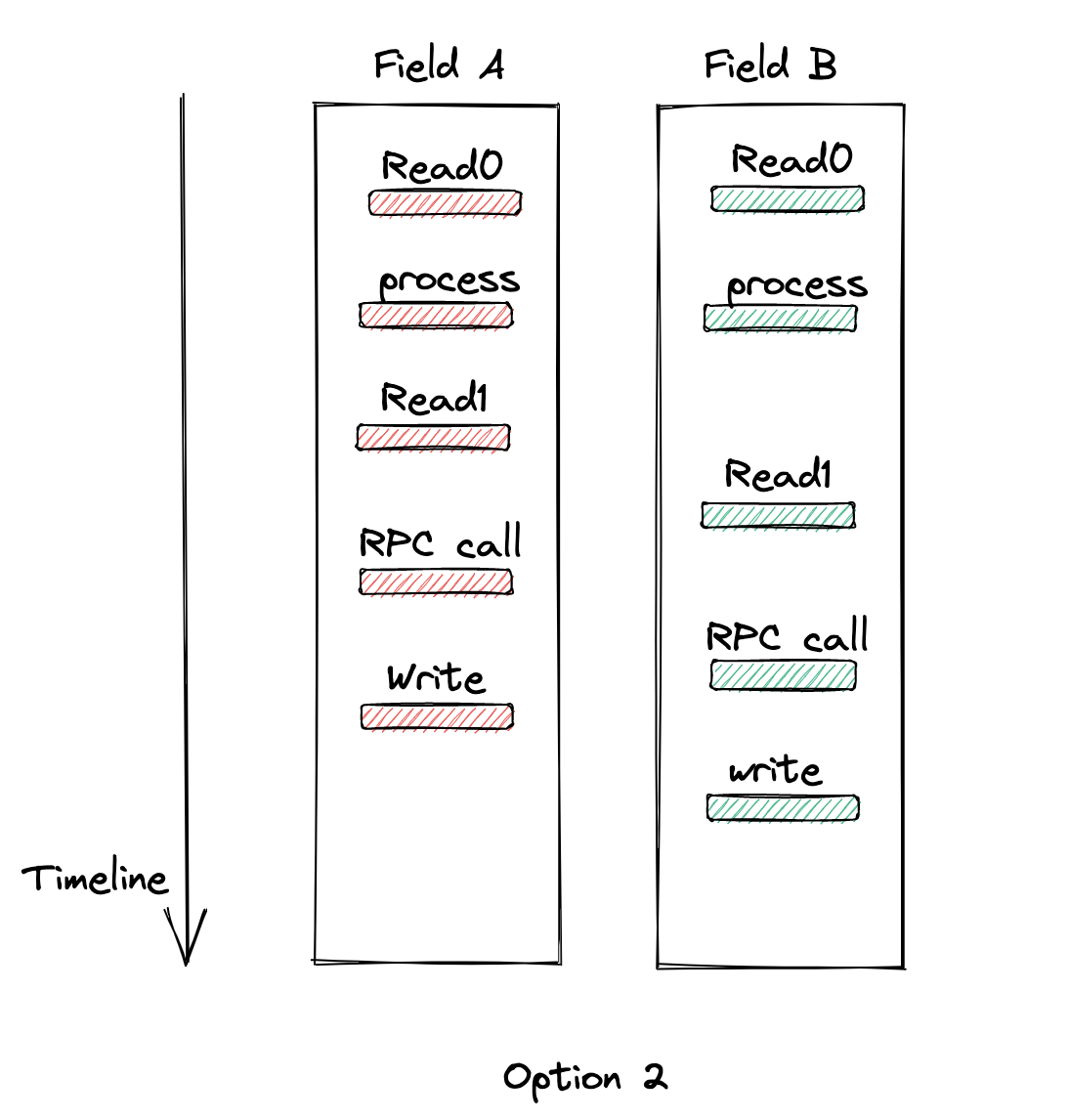
那怎么办呢,总不能在那里一直轮询吧,要轮询多久呢?况且轮询常有但并发不常有,万一没遇上并发岂不是白轮询了?着急去驰骋峡谷的亚瑟说道:实在不行加锁吧?手里的Redis已经跃跃欲试了,此时略加思索后的胖虎拍着亚瑟的肩膀说:我知道你急,但你先别急,且往下看。
Option 3
实际上我们将业务逻辑执行顺序稍作调整就可以解决这个问题,如下图所示:
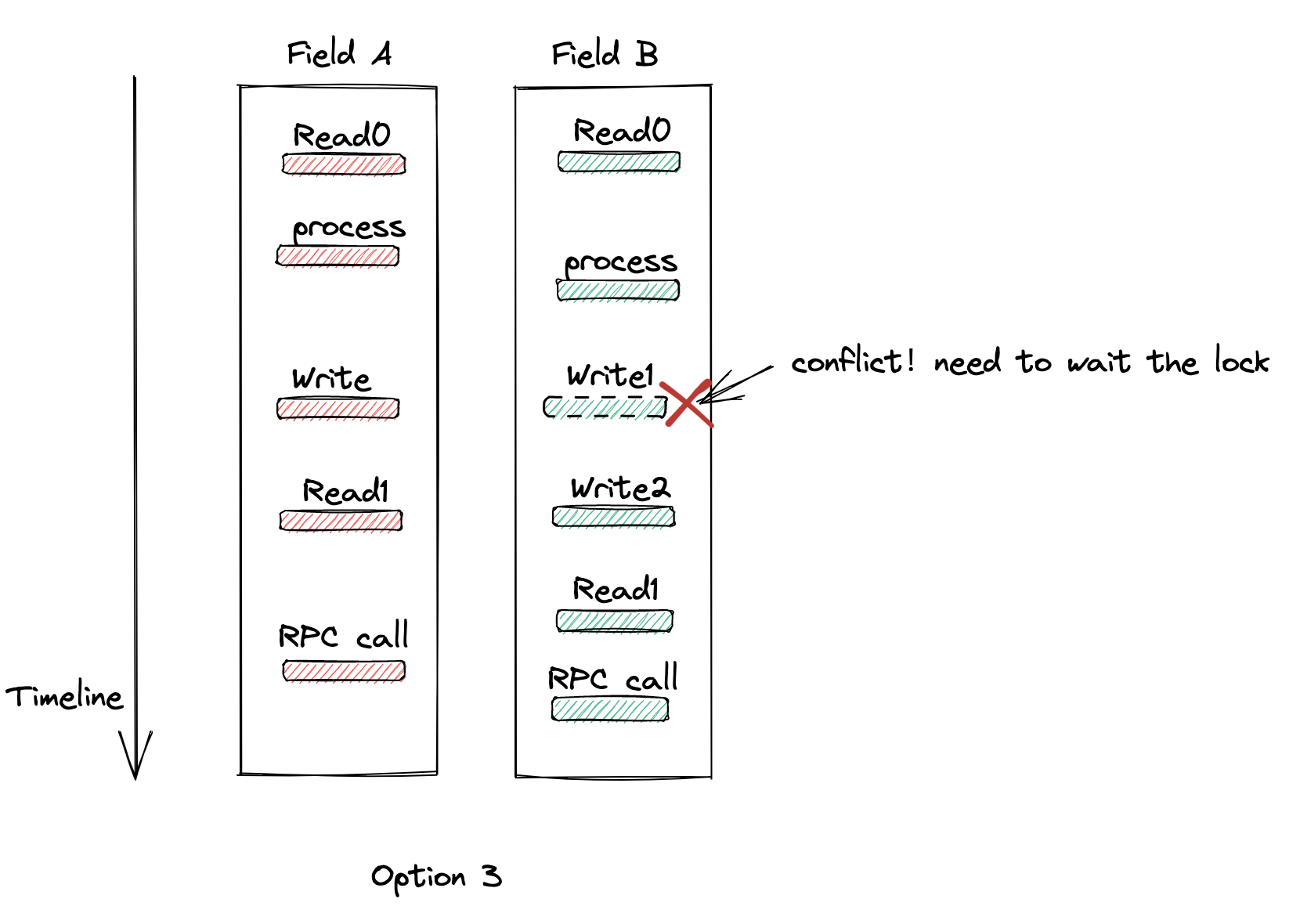
我们将数据的更新操作放在二次查询之前,更新成功之后再查询最新数据并执行后面的通知逻辑。
为什么这样做可以避免上面的问题呢?
应了那句废老话:现在的关键问题是要找到问题的关键😂
问题的关键是在并发的时候需要将两个操作互斥开来,而又因为操作的是同一条记录那数据库的行锁恰好可以利用起来:
当逻辑A和逻辑B同时更新记录时先获取到行锁的会先执行,没有获取到锁的需要等待(通常只更新一条记录等待锁的时间不会很长),这个获取锁的逻辑将两个并发更新变成了串行,又因为更新后再查询了一次最新数据所以可以保证至少有一方逻辑是能获取到对方最新的更新记录,从而解决了这个问题。
总结
看完之后亚瑟说:掰扯了半天这不就是一句select for update可以解决的事吗?
哈哈,说的对但也不完全对。
使用select for update确实可以解决问题,但同时要考虑到这种在第一次查询就加锁的操作如果在业务逻辑复杂的场景下会使得事务变长、持锁的时间变长,增加锁的等待时间进而带来资源的损耗。另外,如果使用的存储并非关系型数据库也不提供for update的语义接口怎么办呢?此时使用上面Option 3的方法只要存储有行锁机制就可以达到select for update的效果。
当然这里有个大前提:两个操作更新的是同一个存储里的同一条数据。那如果是不同数据库里的不同数据呢,亚瑟问到。胖虎笑嘻嘻的说:你腰间不是还别着一把锁呢么~
亚瑟听完开启一技能兴冲冲的奔向了峡谷
望着他远去的背影胖虎脑子里又浮现出另一个topic:分布式系统中数据读写的线性一致性问题
未完待续……
