分词方法分类
中文分词大致分为三类:
- 基于字符串匹配:最大正向匹配法、逆向最大匹配法、最少切分法、双向匹配法等
- 基于统计:基于词频度统计的分词方法
- 基于规则:基于知识理解,利用神经网络等分词方法
语言模型
基于词图的最大概率分词方法源于概率统计语言模型。
从统计思想的角度来看,分词问题的输入是一个字串C=C1,C2,……,Cn,输出是一个词串S=W1,W2,……,Wm,其中m<=n。对于一个特定的字符串C,会有多个切分方案S对应,分词的任务就是在这些S中找出概率最大的一个切分方案,也就是对输入字符串切分出最有可能的词序列。
$$Seg(c)argmax_{S \epsilon G} P(S|C)=argmax_{S \epsilon G}\frac{P(C|S)P(S)}{P(C)}
$$
例如对于输入『小红马上下来』,切分可能有:
- S1: 小红/马上/下来
- S2: 小红马/上/下来
- S3: 小红马/上下/来
- ……
计算条件概率P(S1|C),P(S2|C)和P(S3|C),然后采用概率大的值对应的切分方案。根据贝叶斯公式:
$$P(S|C)=\frac{P(C|S)P(S)}{P(C)}$$
其中P(C)是字符串在语料库中出现的概率为一固定值,从词串恢复到汉字串的概率只有唯一的一种方式,所以P(C|S)=1。因此,比较P(S1|C)和P(S2|C)的大小变成比较P(S1)和P(S2)的大小。
概率语言模型分词的任务是:在全切分所得的所有结果中求某个切分方案S,使得P(S)最大。为了容易实现,假设每个词之间的概率是上下文无关的。(注意此处)
$$P(S)=P(W_1,W_2,W_3 \ldots)=P(W_1)*P(W_2)* \cdots*P(W_m)$$
计算任意一个词出现的概率如下:
$$P(W_i)=\frac{W_i在语料库中出现的次数n_i}{语料库中总词数N}$$
词典
词典中存储了词的text,出现次数,词性等信息,结构如下:
| 词 | 出现次数 | 词性 |
|---|---|---|
| 小红马 | 113 | nr |
| 巴塞尔 | 113 | nr |
| 巴塞爾 | 113 | nr |
| 文明史 | 113 | nr |
为了能够快速查找字典采用双数组Trie树来存储,关于Trie树相关内容请自行百度。
构建词图
根据字典构建的trie树,扫描待分词句子生成DAG(有向无环图),就是对待分词句子,根据给定的词典进行查词典操作,找出所有可能的句子切分。
如果待切分的字符串有m个字符,考虑每个字符左边和右边的位置,则有m+1个点对应,点的编号从0到m。把候选词看成边,可以根据词典生成一个切分词图。例如『小红马上下来』形成的词图如下:
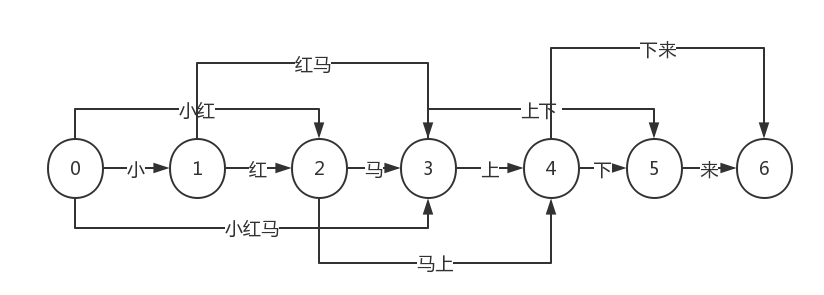
路径1: 0-3-4-6 小红马/上/下来
路径2: 0-2-4-6 小红/马上/下来
……
切分词图中的边都是词典中的词,边的起点和终点分别是词的开始和结束位置。
计算最大概率
因为假设每个词之间的概率是上下文无关的,因此满足动态规划求解所要求的最优子结构性质和无后效性。求出值最大的P(Si)后,利用回溯的方法直接输出Si。图用邻接矩阵存储,伪代码如下:
1 |
|
从右向左扫描是因为汉语句子的重心经常落在后面,这种扫描方式能提高分词的准确性。
最后
该模型有一个前提条件:『假设每个词之间的概率是上下文无关的』,这一点是不严谨的,一句话当中相邻词之间上下文无关很难做到。
搜索引擎中的中文分词十分复杂,分词的过程中需要考虑:
- 切分的正确性
- 粒度的合理性
- 切分的一致性
- 词条关系分析
- 词条属性分析
- 歧义词处理
- ……
