背景
近几年随着大量数据的积累和算力的发展使AI有了更多的落地场景并再次成为人们口中的“明日之星”,这其中云计算是其背后的一个重要推手。而云计算领域Kubernetes作为云OS的事实标准也成为了关注的焦点,云原生和AI的快速发展使得用Kubernetes管理GPU的诉求也越来越多,使用Kubernetes管理GPU有什么好处呢?
首先,使用k8s管理GPU可以加速部署。使用容器技术可以将部署的过程固化以复用,减少准备部署环境所耗费的时间,目前许多AI框架都提供相关的容器镜像。
其次,提升资源使用率。当公司的GPU资源达到一定数量后通过k8s统一资源调度将GPU资源池化,进行分时复用,使得GPU可以用时申请,用完释放提升GPU使用效率降低成本。
最后,通过容器化可以将GPU资源进行隔离,有效的防止各任务之间的相互影响,提升系统的稳定性。
Docker下如何使用GPU
首先我们看一下如何在Docker容器里使用GPU,要在Docker容器里使用GPU主要有两点:
- GPU Device,在容器里能够找到 GPU设备,比如:/dev/nvidia0
GPU驱动,在容器里能够找到对应的GPU驱动目录,比如:/usr/local/nvidia/*
以上两点可以通过配置docker启动参数来实现,GPU设备路径可以通过容器启动时Devices参数来配置,设备驱动目录可以通过容器启动时Volume参数来配置。
准备相关的Docker镜像有两种方式:
- 下载官方镜像
比如TensorFlow、PyTorch、Caffe等均提供了官方的镜像可在docker.hub上下载,简单便捷。
- 基于Nvidia CUDA基础镜像进行构建
如果因官方镜像无法满足需求而对其进行了改动那么就需要自己来构建镜像,在这种情况下最好是以NVIDIA 官方镜像为基础镜像来进行构建。例如PyTorch就是以nvidia cuda为基础镜像来构建的:
1 | FROM nvidia/cuda:10.1-cudnn7-devel-ubuntu16.04 |
Nvidia-docker原理
以上我们了解了在Docker中使用GPU的关键点,与在物理机中直接使用GPU的区别如下图:
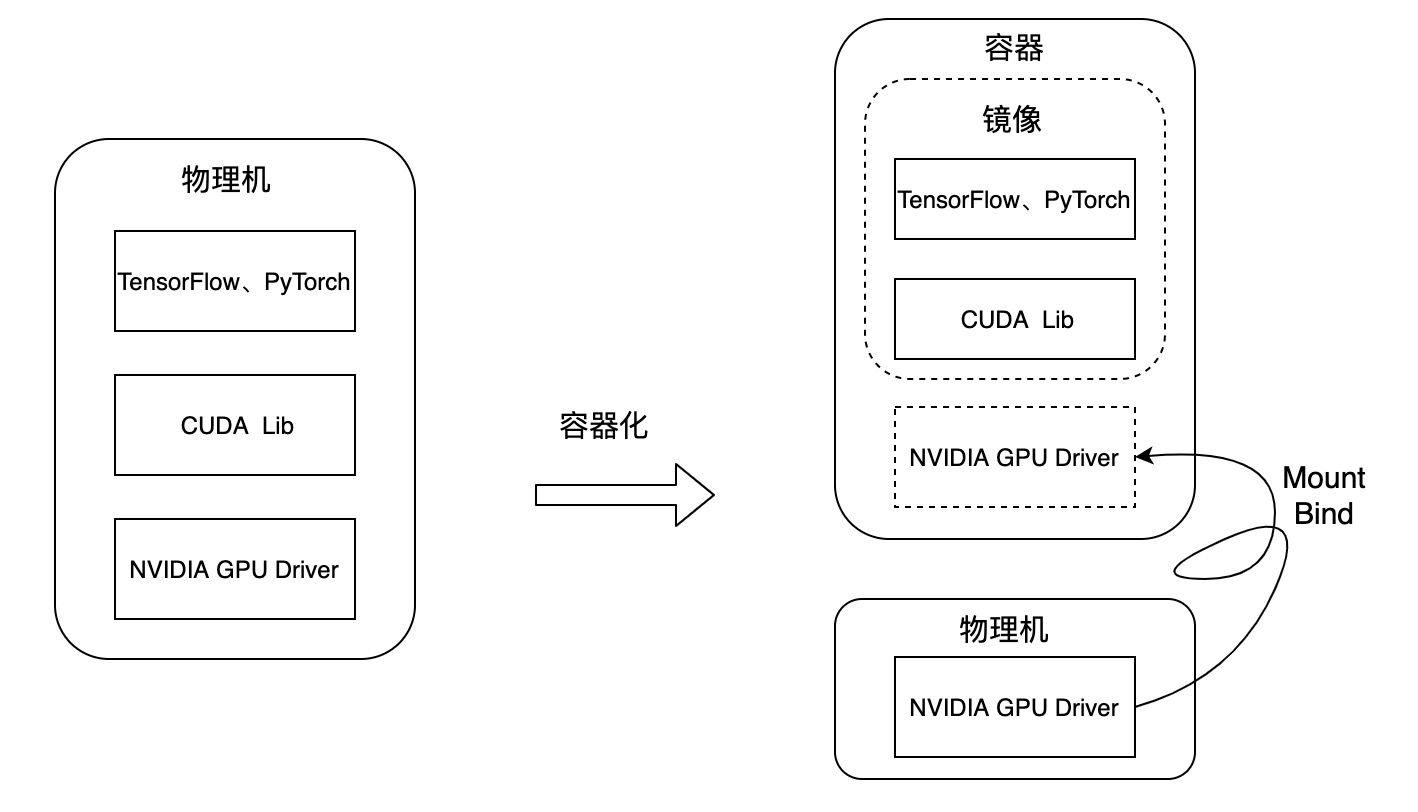
要在物理机里运行一个AI程序,其运行环境如图左侧所示,首先底层是GPU的驱动,再往上是cuda lib,在cuda之上是基于TensorFlow、PyTorch等框架的应用,通常情况下AI应用框架对cuda库的版本有要求,如果AI应用框架版本变化后对应的cuda版本也要跟着变化,二者耦合较紧,而底层的GPU驱动则不会有大的变化。
如上图右侧所示,NVIDIA GPU容器化的方案是将GPU驱动安装到宿主机,将cuda lib及TensorFlow、PyTorch等打到镜像中,使用该镜像运行容器时将GPU驱动映射到容器中,这样就可以在一台宿主机上运行不同版本的cuda及对应的应用容器。
大家习惯使用 Nvidia-docker 来运行 GPU 容器,而 Nvidia-docker 的实际工作就是来自动化将宿主机的设备和 Nvidia 驱动库映射到容器中。
k8s Device Plugin原理
当使用K8S时我们期望在pod的对象里声明需要的GPU资源后k8s在调度时即可为我们分配所需的GPU资源,如:
1 |
|
在上述 Pod 的 limits 字段里,这个资源的名称是nvidia.com/gpu,它的值是 1。即这个 Pod 声明了自己要使用一个 NVIDIA 类型的 GPU。这当中使用了一种叫作 Extended Resource特殊字段来传递所需GPU信息。
为了能够让kube-scheduler知道每台宿主机GPU资源可用量就需要宿主机能够向API Server汇报自己的该类型资源的可用量,每种资源的可用量实际表现为Node对象Status字段的内容:
1 | apiVersion: v1 |
那么如何为Node对象添加GPU资源的可用量呢?有两种方式:
- Extend Resources 属于 Node-level 的 api,完全可以独立于 Device Plugin 使用,只需通过一个 PACTH API 对 Node 对象进行 status 部分更新即可。这样在 Kubernetes 调度器中就能够记录这个节点的 GPU 类型,它所对应的资源数量是 1。
1 | $ curl --header "Content-Type: application/json-patch+json" \ |
- 使用Device Plugin,在k8s中所有硬件资源的管理都是通过Deveice Plugin插件来完成的,这当中当然也包括对Extended Resource汇报的逻辑,如下图所示:
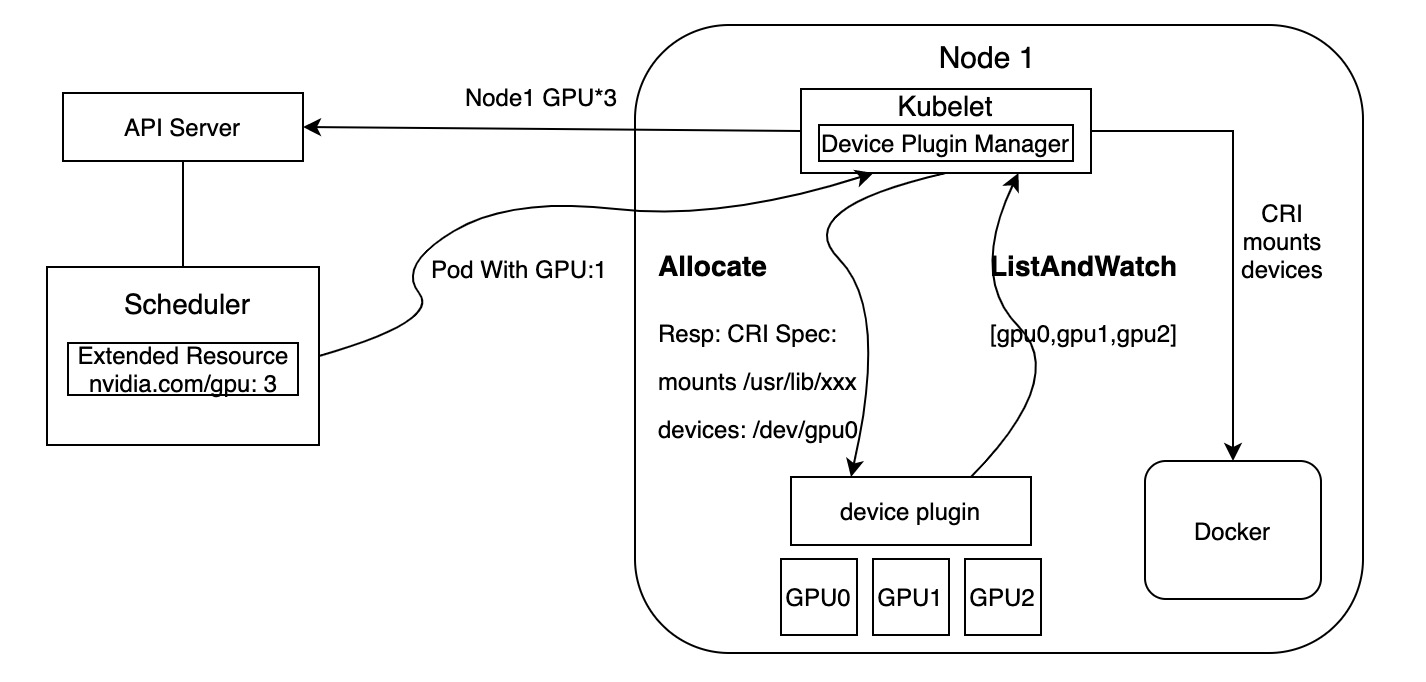
Device Plugin的工作主要分为两部分:资源上报和资源使用时的调度。
资源上报
首先Device Plugin通过GRPC与kubelet的Device Plugin Manager进行通信并将自己注册给k8s,让kubelet知道三件事:我是谁,即该Device Plugin管理的设备是什么;我在哪,即Device Plugin所监听的socket所在位置,kubelet通过此来进行调用Device Plugin;交互协议,即API版本号;
然后Device Plugin启动一个GRPC Server让kubelet来访问。
第三步,kubelet与Device Plugin建立一个 ListAndWatch的长连接,用来发现设备 ID 以及设备的健康状态,Device Plugin定期向 kubelet 汇报该 Node 上 GPU 的列表。
第四步,kubelet 会将这些设备暴露到 Node 节点的状态中,在kubelet向 api-server发送心跳里以 Extended Resource 的方式,加上这些 GPU 的数量,比如nvidia.com/gpu=3。后续调度器可以根据这些信息进行调度。
kubelet 在向 api-server 进行汇报的时候,只会汇报该 GPU 对应的数量。而 kubelet 自身的 Device Plugin Manager 会对这个 GPU 的 ID 列表进行保存,并用来具体的设备分配。而对于 Kubernetes scheduler来说,它不知道这个 GPU 的 ID 列表,它只知道 GPU 的数量。
资源调度使用
当某个pod要使用GPU资源时只需要在api对象里声明所需资源的数量,接下来scheduler会在自己缓存里找到能够满足要求的node,然后将其GPU减掉相应的数量并完成node与pod的绑定。
当kubelet发现该pod被分配到自己的节点上时会从自己持有的GPU列表里为该pod分配一个GPU,此时kubelet向Device Plugin发起Allocate()请求,参数为分配给该pod的设备id。当 Device Plugin 收到 Allocate 请求之后根据 kubelet 传递过来的设备 ID找到这些设备对应的设备路径和驱动目录。这些信息正是 Device Plugin 周期性的从本机查询到的。比如,在 NVIDIA Device Plugin 的实现里它会定期访问 nvidia-docker 插件,从而获取到本机的 GPU 信息。
被分配 的GPU 对应的设备路径和驱动目录信息被返回给 kubelet 之后就完成了为一个容器分配 GPU 的操作。接下来,kubelet 会把这些信息追加在创建该容器所对应的 CRI(Container Runtime Interface)请求当中。当这个 CRI 请求发给 Docker 之后,Docker 为你创建出来的容器里就会出现这个 GPU 设备,并把它所需要的驱动目录挂载进去。这个过程与上面提到的通过docker启动参数挂载设备和驱动原理是一致的。
至此通过k8s为一个pod分配GPU的过程就完成了。
Device Pulgin的不足
虽然通过Device Plugin可以让k8s在调度时一定程度上满足Extended Resource的调度,但也只是基于数量调度,如果设备是异构的、硬件的属性比较复杂并且pod也关心硬件的某些属性,那么不能简单的通过数量来进行调度此时这个方案就不能满足需求,另外对于资源分配时quota限制粒度也较大。
针对以上问题目前有一种方案通过node label和node selector来解决该问题,但这种方式也只能通过将同一种类型的硬件挂载到同一个节点来解决对某种类型资源的分配,不能使其他更详细资源属性参与到调度中,比如:某个节点挂载了显存不同的NVIDIA Tesla K80,某个应用想要使用显存大于10G的GPU。
另外一种方案是通过CRD(CustomResourceDefinition)以及Scheduler Extender 机制来满足异构设备调度的需求,但多多少少都会涉及到改动k8s源码。
因此目前为止官方提供的Device Plugin可以用来进行设备的管理和资源分配但在调度方面由于向scheduler暴露的设备属性信息太少还无法满足复杂的调度需求。
